Note
Click here to download the full example code
Radar plots
In this lesson, we go step-by-step through the process of making player radars for a striker. We calculate the following metrics directly from a count of actions in the Wyscout event data,
Non-penalty goals
Assists
Key passes
Smart passes
Ariel duels won
Ground attacking duels won
We add tho these our own calculations of,
non-penalty expected goals.
passes ending in final third
receptions in final third.
import pandas as pd
import numpy as np
import json
# plotting
import matplotlib.pyplot as plt
# statistical fitting of models
import statsmodels.api as sm
import statsmodels.formula.api as smf
#opening data
import os
import pathlib
import warnings
#used for plots
from scipy import stats
from mplsoccer import PyPizza, FontManager
pd.options.mode.chained_assignment = None
warnings.filterwarnings('ignore')
Opening data
For this task we will use Wyscout data. We open it, save in the dataframe train. To avoid potential errors, we keep only the data for which the beginning and end of an action was registered.
train = pd.DataFrame()
for i in range(13):
file_name = 'events_England_' + str(i+1) + '.json'
path = os.path.join(str(pathlib.Path().resolve().parents[0]), 'data', 'Wyscout', file_name)
with open(path) as f:
data = json.load(f)
train = pd.concat([train, pd.DataFrame(data)], ignore_index = True)
#potential data collection error handling
train = train.loc[train.apply (lambda x: len(x.positions) == 2, axis = 1)]
Calculating xG value
As one of the pieces of our radar plot we want to use the Expected Goals statistic. We build 2 different models for headers and shots with leg. Then, the statistic is calculated. If we want to use non-penalty xG, we can set the npxG value of function to True. We calculate the cummulative xG for all players and return the dataframe only with playerId and this value.
This uses the same method as in lesson 2 to caluclate xG
def calulatexG(df, npxG):
"""
Parameters
----------
df : dataframe
dataframe with Wyscout event data.
npxG : boolean
True if xG should not include penalties, False elsewhere.
Returns
-------
xG_sum: dataframe
dataframe with sum of Expected Goals for players during the season.
"""
#very basic xG model based on
shots = df.loc[df["eventName"] == "Shot"].copy()
shots["X"] = shots.positions.apply(lambda cell: (100 - cell[0]['x']) * 105/100)
shots["Y"] = shots.positions.apply(lambda cell: cell[0]['y'] * 68/100)
shots["C"] = shots.positions.apply(lambda cell: abs(cell[0]['y'] - 50) * 68/100)
#calculate distance and angle
shots["Distance"] = np.sqrt(shots["X"]**2 + shots["C"]**2)
shots["Angle"] = np.where(np.arctan(7.32 * shots["X"] / (shots["X"]**2 + shots["C"]**2 - (7.32/2)**2)) > 0, np.arctan(7.32 * shots["X"] /(shots["X"]**2 + shots["C"]**2 - (7.32/2)**2)), np.arctan(7.32 * shots["X"] /(shots["X"]**2 + shots["C"]**2 - (7.32/2)**2)) + np.pi)
#if you ever encounter problems (like you have seen that model treats 0 as 1 and 1 as 0) while modelling - change the dependant variable to object
shots["Goal"] = shots.tags.apply(lambda x: 1 if {'id':101} in x else 0).astype(object)
#headers have id = 403
headers = shots.loc[shots.apply (lambda x:{'id':403} in x.tags, axis = 1)]
non_headers = shots.drop(headers.index)
headers_model = smf.glm(formula="Goal ~ Distance + Angle" , data=headers,
family=sm.families.Binomial()).fit()
#non-headers
nonheaders_model = smf.glm(formula="Goal ~ Distance + Angle" , data=non_headers,
family=sm.families.Binomial()).fit()
#assigning xG
#headers
b_head = headers_model.params
xG = 1/(1+np.exp(b_head[0]+b_head[1]*headers['Distance'] + b_head[2]*headers['Angle']))
headers = headers.assign(xG = xG)
#non-headers
b_nhead = nonheaders_model.params
xG = 1/(1+np.exp(b_nhead[0]+b_nhead[1]*non_headers['Distance'] + b_nhead[2]*non_headers['Angle']))
non_headers = non_headers.assign(xG = xG)
if npxG == False:
#find pens
penalties = df.loc[df["subEventName"] == "Penalty"]
#assign 0.8
penalties = penalties.assign(xG = 0.8)
#concat, group and sum
all_shots_xg = pd.concat([non_headers[["playerId", "xG"]], headers[["playerId", "xG"]], penalties[["playerId", "xG"]]])
xG_sum = all_shots_xg.groupby(["playerId"])["xG"].sum().sort_values(ascending = False).reset_index()
else:
#concat, group and sum
all_shots_xg = pd.concat([non_headers[["playerId", "xG"]], headers[["playerId", "xG"]]])
all_shots_xg.rename(columns = {"xG": "npxG"}, inplace = True)
xG_sum = all_shots_xg.groupby(["playerId"])["npxG"].sum().sort_values(ascending = False).reset_index()
#group by player and sum
return xG_sum
#making function
npxg = calulatexG(train, npxG = True)
#investigate structure
npxg.head(3)
Calculating passes ending in final third and receptions in final third
These 2 statistics capture how good a player is in receiving and passing th ball in the final third. These statistics add context to passes. It isn’t enough for a striker to be a good passer of the ball he or she should be able to perform well in the final third.
To get the information about receptions, the basic idea is that the player who made the next action was the receiver. We filter successful passes that ended in the final third and get the passes as well as the receiver. As in the last step, we sum them by player and merge these dataframes to return one. Note that we use outer join not to forget a player who made no receptions in the final third, bud did make some passes.
def FinalThird(df):
"""
Parameters
----------
df : dataframe
dataframe with Wyscout event data.
Returns
-------
final_third: dataframe
dataframe with number of passes ending in final third and receptions in that area for a player.
"""
df = df.copy()
#need player who had received the ball
df["nextPlayerId"] = df["playerId"].shift(-1)
passes = df.loc[train["eventName"] == "Pass"].copy()
#changing coordinates
passes["x"] = passes.positions.apply(lambda cell: (cell[0]['x']) * 105/100)
passes["y"] = passes.positions.apply(lambda cell: (100 - cell[0]['y']) * 68/100)
passes["end_x"] = passes.positions.apply(lambda cell: (cell[1]['x']) * 105/100)
passes["end_y"] = passes.positions.apply(lambda cell: (100 - cell[1]['y']) * 68/100)
#get accurate passes
accurate_passes = passes.loc[passes.apply (lambda x:{'id':1801} in x.tags, axis = 1)]
#get passes into final third
final_third_passes = accurate_passes.loc[accurate_passes["end_x"] > 2*105/3]
#passes into final third by player
ftp_player = final_third_passes.groupby(["playerId"]).end_x.count().reset_index()
ftp_player.rename(columns = {'end_x':'final_third_passes'}, inplace=True)
#receptions of accurate passes in the final third
rtp_player = final_third_passes.groupby(["nextPlayerId"]).end_x.count().reset_index()
rtp_player.rename(columns = {'end_x':'final_third_receptions', "nextPlayerId": "playerId"}, inplace=True)
#outer join not to lose values
final_third = ftp_player.merge(rtp_player, how = "outer", on = ["playerId"])
return final_third
final_third = FinalThird(train)
#investigate structure
final_third.head(3)
Calculating air and ground duels won
To our chart we would as well add number of duels won, but want to differentiate between air and attacking ground duels - many of them will be dribbles. The deifinition of Wyscout duel can be found here. Both for air duels and attacking ground duels we repeat the next steps - we sum them by player and outer join two dataframes.
def wonDuels(df):
"""
Parameters
----------
df : dataframe
dataframe with Wyscout event data.
Returns
-------
duels_won: dataframe
dataframe with number of won air and ground duels for a player
"""
#find air duels
air_duels = df.loc[df["subEventName"] == "Air duel"]
#703 is the id of a won duel
won_air_duels = air_duels.loc[air_duels.apply (lambda x:{'id':703} in x.tags, axis = 1)]
#group and sum air duels
wad_player = won_air_duels.groupby(["playerId"]).eventId.count().reset_index()
wad_player.rename(columns = {'eventId':'air_duels_won'}, inplace=True)
#find ground duels won
ground_duels = df.loc[df["subEventName"].isin(["Ground attacking duel"])]
won_ground_duels = ground_duels.loc[ground_duels.apply (lambda x:{'id':703} in x.tags, axis = 1)]
wgd_player = won_ground_duels.groupby(["playerId"]).eventId.count().reset_index()
wgd_player.rename(columns = {'eventId':'ground_duels_won'}, inplace=True)
#outer join
duels_won = wgd_player.merge(wad_player, how = "outer", on = ["playerId"])
return duels_won
duels = wonDuels(train)
#investigate structure
duels.head(3)
Calculating smart passes
Another statistic that we want to add are accurate smart passes. Those are the passes that break the opponent defensive line. The exact deifinition of Wyscout smart pass can be found here. Also in this case, we sum smart passes by player.
def smartPasses(df):
"""
Parameters
----------
df : dataframe
dataframe with Wyscout event data.
Returns
-------
sp_player: dataframe
dataframe with number of smart passes.
"""
#get smart passes
smart_passes = df.loc[df["subEventName"] == "Smart pass"]
#find accurate
smart_passes_made = smart_passes.loc[smart_passes.apply (lambda x:{'id':1801} in x.tags, axis = 1)]
#sum by player
sp_player = smart_passes_made.groupby(["playerId"]).eventId.count().reset_index()
sp_player.rename(columns = {'eventId':'smart_passes'}, inplace=True)
return sp_player
smart_passes = smartPasses(train)
#investigate structure
smart_passes.head(3)
Calculating smart passes
Our radar plots wouldn’t be completed without non-penalty goals, assists and key passes. To sum them, we repeat steps previosuly described.
def GoalsAssistsKeyPasses(df):
"""
Parameters
----------
df : dataframe
dataframe with Wyscout event data.
Returns
-------
data: dataframe
dataframe with number of (non-penalty) goals, assists and key passes.
"""
#get goals
shots = df.loc[df["subEventName"] == "Shot"]
goals = shots.loc[shots.apply (lambda x:{'id':101} in x.tags, axis = 1)]
#get assists
passes = df.loc[df["eventName"] == "Pass"]
assists = passes.loc[passes.apply (lambda x:{'id':301} in x.tags, axis = 1)]
#get key passes
key_passes = passes.loc[passes.apply (lambda x:{'id':302} in x.tags, axis = 1)]
#goals by player
g_player = goals.groupby(["playerId"]).eventId.count().reset_index()
g_player.rename(columns = {'eventId':'goals'}, inplace=True)
#assists by player
a_player = assists.groupby(["playerId"]).eventId.count().reset_index()
a_player.rename(columns = {'eventId':'assists'}, inplace=True)
#key passes by player
kp_player = key_passes.groupby(["playerId"]).eventId.count().reset_index()
kp_player.rename(columns = {'eventId':'key_passes'}, inplace=True)
data = g_player.merge(a_player, how = "outer", on = ["playerId"]).merge(kp_player, how = "outer", on = ["playerId"])
return data
gakp = GoalsAssistsKeyPasses(train)
#investigate structure
gakp.head(3)
Minutes played
All data on our plot will be per 90 minutes played. Therefore, we need an information on the number of minutes played throughout the season. To do so, we will use a prepared file that bases on the idea developed by students taking part in course in 2021. Files with miutes per game for players in top 5 leagues can be found here. After downloading data and saving it in out directory, we open it and store in a dataframe. Then we calculate the sum of miutes played in a season for each player.
path = os.path.join(str(pathlib.Path().resolve().parents[0]),"minutes_played", 'minutes_played_per_game_England.json')
with open(path) as f:
minutes_per_game = json.load(f)
minutes_per_game = pd.DataFrame(minutes_per_game)
minutes = minutes_per_game.groupby(["playerId"]).minutesPlayed.sum().reset_index()
Summary table
To make our radar plots we need to first prepare the data with previously calculated statistics. We left join (too keep all the players). Also, we right join minutes, because there may be some players who were on the pitch but didn’t make an action. Then, the na observations are filled with zeros (if there was NA scored goals it meant). Moreover, we filter out players who played 400 miutes or less.
players = train["playerId"].unique()
summary = pd.DataFrame(players, columns = ["playerId"])
summary = summary.merge(npxg, how = "left", on = ["playerId"]).merge(final_third, how = "left", on = ["playerId"]).merge(duels, how = "left", on = ["playerId"]).merge(smart_passes, how = "left", on = ["playerId"]).merge(gakp, how = "left", on = ["playerId"])
summary = minutes.merge(summary, how = "left", on = ["playerId"])
summary = summary.fillna(0)
summary = summary.loc[summary["minutesPlayed"] > 400]
Filtering positions
Since we would like to create a plot with attacking values, it is important to keep only forwards (also the player that we will make the plot for is a forward). Therefore, we open the players dataset, we filter out forwards and inner join it with our summary dataframe to keep only Premier League forwards who played more than 400 minutes.
path = os.path.join(str(pathlib.Path().resolve().parents[0]),"data", 'Wyscout', 'players.json')
with open(path) as f:
players = json.load(f)
player_df = pd.DataFrame(players)
forwards = player_df.loc[player_df.apply(lambda x: x.role["name"] == "Forward", axis = 1)]
forwards.rename(columns = {'wyId':'playerId'}, inplace=True)
to_merge = forwards[['playerId', 'shortName']]
summary = summary.merge(to_merge, how = "inner", on = ["playerId"])
Calculating statistics per 90
To adjust the data for different number of minutes played, we calculate each statistic we want to plot per 90 minutes player. That means that we multiply it by 90 and divide by the total number of minutes played by player.
summary_per_90 = pd.DataFrame()
summary_per_90["shortName"] = summary["shortName"]
for column in summary.columns[2:-1]:
summary_per_90[column + "_per90"] = summary.apply(lambda x: x[column]*90/x["minutesPlayed"], axis = 1)
Finding values for player
For this tutorial we decided to use Mohammed Salah as our player. First, we have to find his shortName in the summary database. Then, we filter in the dataframe with data per 90 his statistics. As the next step we store these statistics in a list and calculate in which percentile is the value. Since the distribution of statistics may not be uniform on the interval [minimum value - maximum value], we claim that is better to use them as the size of piece on our radar.
#player to investigate - Mohammed Salah
#only his statistics
salah = summary_per_90.loc[summary_per_90["shortName"] == "Mohamed Salah"]
#columns similar together
salah = salah[['npxG_per90', "goals_per90", "assists_per90", "key_passes_per90", "smart_passes_per90", "final_third_passes_per90", "final_third_receptions_per90", "ground_duels_won_per90", "air_duels_won_per90"]]
#take only necessary columns - exclude playerId
per_90_columns = salah.columns[:]
#values to mark on the plot
values = [round(salah[column].iloc[0],2) for column in per_90_columns]
#percentiles
percentiles = [int(stats.percentileofscore(summary_per_90[column], salah[column].iloc[0])) for column in per_90_columns]
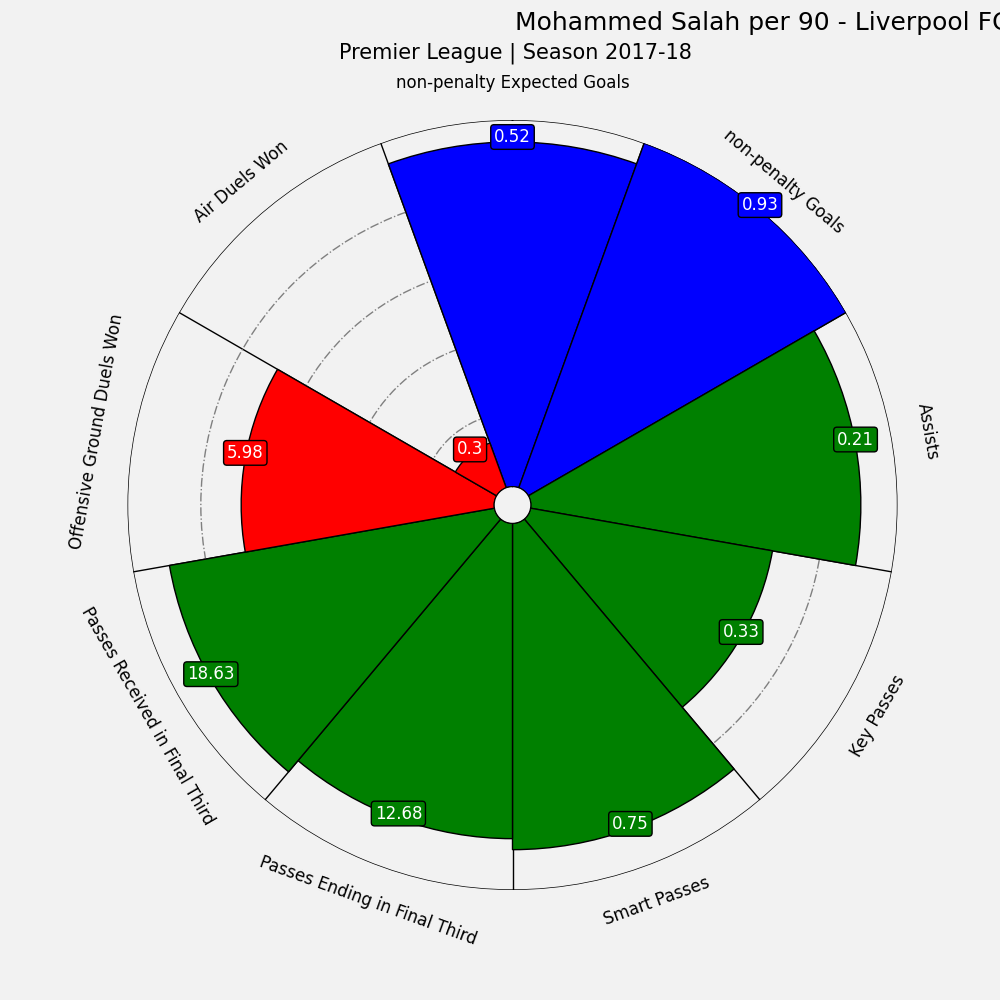
Making radar charts
To plot our radar charts we use mplsoccer and their amazing tutorials. First we take a list of names that we would like to to describe the statistics. Then, we download fonts using mplsoccer FontManager to make our plot look nicer/ As the next step we declare a PyPizza object which would make a pizza-like radar plot, but in the mplsoccer library there are also different options avaliable. Then, we make a pizza plot with our data using make_pizza method. to put our data on the plot. Note, as mention before, that the size of our pizza piece is the percentile. Therefore, to put the statistic on the plot, we put the statistic on it. Then, we add title and subtitle to our plot.
#list of names on plots
names = ["non-penalty Expected Goals", "non-penalty Goals", "Assists", "Key Passes", "Smart Passes", "Passes Ending in Final Third", "Passes Received in Final Third", "Offensive Ground Duels Won", "Air Duels Won"]
slice_colors = ["blue"] * 2 + ["green"] * 5 + ["red"] * 2
text_colors = ["white"]*9
#PIZZA PLOT
baker = PyPizza(
params=names,
min_range = None,
max_range = None, # list of parameters
straight_line_color="#000000", # color for straight lines
straight_line_lw=1, # linewidth for straight lines
last_circle_lw=1, # linewidth of last circle
other_circle_lw=1, # linewidth for other circles
other_circle_ls="-." # linestyle for other circles
)
#making pizza for our data
fig, ax = baker.make_pizza(
percentiles, # list of values
figsize=(10, 10), # adjust figsize according to your need
param_location=110,
slice_colors=slice_colors,
value_colors = text_colors,
value_bck_colors=slice_colors, # where the parameters will be added
kwargs_slices=dict(
facecolor="cornflowerblue", edgecolor="#000000",
zorder=2, linewidth=1
), # values to be used when plotting slices
kwargs_params=dict(
color="#000000", fontsize=12, va="center"
), # values to be used when adding parameter
kwargs_values=dict(
color="#000000", fontsize=12,
bbox=dict(
edgecolor="#000000", facecolor="cornflowerblue",
boxstyle="round,pad=0.2", lw=1
)
) # values to be used when adding parameter-values
)
#putting text
texts = baker.get_value_texts()
for i, text in enumerate(texts):
text.set_text(str(values[i]))
# add title
fig.text(
0.515, 0.97, "Mohammed Salah per 90 - Liverpool FC", size=18
)
# add subtitle
fig.text(
0.515, 0.942,
"Premier League | Season 2017-18",
size=15,
ha="center", color="#000000"
)
plt.show()
Calculating possession
As the next step we would like to adjust our plot by the player’s team ball possesion while they were on the pitch. To do it, for each row of our dataframe with minutes per player per each game we take all the events that were made in this game while the player was on the pitch. We will also use duels, but don’t include lost air duels and lost ground defending duels. Why? Possesion is calculated as number of touches by team divided by the number all touches. If a player lost ground defending duel, that means that he could have been dribbled by, so he did not touch the ball. If they lost the air duel, they lost a header. Therefore, we claim that those were mostly events where player may have not touched the ball (or if he did the team did not take control over it). We sum both team passes and these duels and all passes and these duels in this period. We store these values in a dictionary. Then, summing them for each player separately and calculating their ratio, we get the possesion of the ball by player’s team while he was on the pitch. As the last step we merge it with our summary dataframe.
possesion_dict = {}
#for every row in the dataframe
for i, row in minutes_per_game.iterrows():
#take player id, team id and match id, minute in and minute out
player_id, team_id, match_id = row["playerId"], row["teamId"], row["matchId"]
#create a key in dictionary if player encounterd first time
if not str(player_id) in possesion_dict.keys():
possesion_dict[str(player_id)] = {'team_passes': 0, 'all_passes' : 0}
min_in = row["player_in_min"]*60
min_out = row["player_out_min"]*60
#get the dataframe of events from the game
match_df = train.loc[train["matchId"] == match_id].copy()
#add to 2H the highest value of 1H
match_df.loc[match_df["matchPeriod"] == "2H", 'eventSec'] = match_df.loc[match_df["matchPeriod"] == "2H", 'eventSec'] + match_df.loc[match_df["matchPeriod"] == "1H"]["eventSec"].iloc[-1]
#take all events from this game and this period
player_in_match_df = match_df.loc[match_df["eventSec"] > min_in].loc[match_df["eventSec"] <= min_out]
#take all passes and won duels as described
all_passes = player_in_match_df.loc[player_in_match_df["eventName"].isin(["Pass", "Duel"])]
#adjusting for no passes in this period (Tuanzebe)
if len(all_passes) > 0:
#removing lost air duels
no_contact = all_passes.loc[all_passes["subEventName"].isin(["Air duel", "Ground defending duel","Ground loose ball duel"])].loc[all_passes.apply(lambda x:{'id':701} in x.tags, axis = 1)]
all_passes = all_passes.drop(no_contact.index)
#take team passes
team_passes = all_passes.loc[all_passes["teamId"] == team_id]
#append it {player id: {team passes: sum, all passes : sum}}
possesion_dict[str(player_id)]["team_passes"] += len(team_passes)
possesion_dict[str(player_id)]["all_passes"] += len(all_passes)
#calculate possesion for each player
percentage_dict = {key: value["team_passes"]/value["all_passes"] if value["all_passes"] > 0 else 0 for key, value in possesion_dict.items()}
#create a dataframe
percentage_df = pd.DataFrame(percentage_dict.items(), columns = ["playerId", "possesion"])
percentage_df["playerId"] = percentage_df["playerId"].astype(int)
#merge it
summary = summary.merge(percentage_df, how = "left", on = ["playerId"])
Adjusting data for possession
Since we would like to adjust our values by possession, we divide the total statistics by the possesion while player was on the pitch during the entire season. To normalize the values per 90 minutes player we repeat the multiplication by 90 and division by minutes played.
#create a new dataframe only for it
summary_adjusted = pd.DataFrame()
summary_adjusted["shortName"] = summary["shortName"]
#calculate value adjusted
for column in summary.columns[2:11]:
summary_adjusted[column + "_adjusted_per90"] = summary.apply(lambda x: (x[column]/x["possesion"])*90/x["minutesPlayed"], axis = 1)
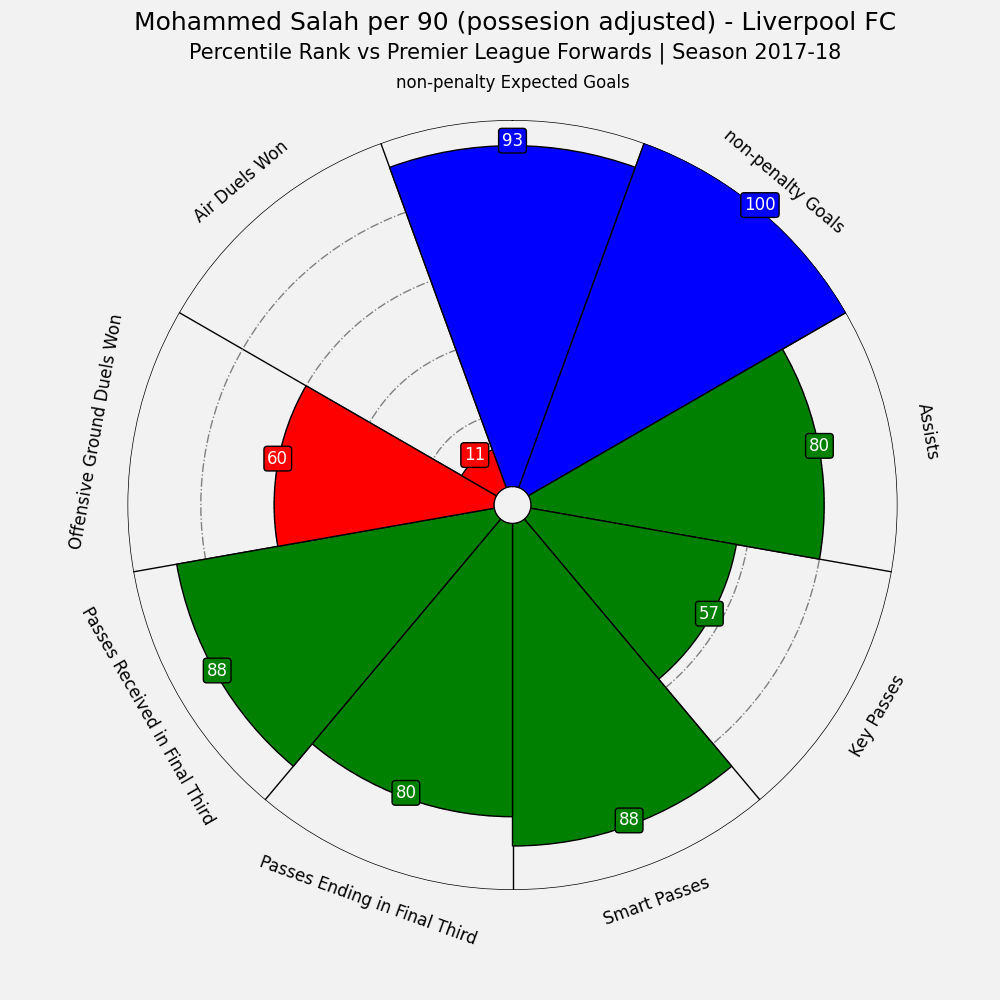
Making the plot with adjusted data for Mohammed Salah
After calculating the values, we repeat the steps by calculating percentiles and plotting radars from making the plot per 90. Note that this time we show the percentile rank on the plot.
salah_adjusted = summary_adjusted.loc[summary_adjusted["shortName"] == "Mohamed Salah"]
salah_adjusted = salah_adjusted[['npxG_adjusted_per90', "goals_adjusted_per90", "assists_adjusted_per90", "key_passes_adjusted_per90", "smart_passes_adjusted_per90", "final_third_passes_adjusted_per90", "final_third_receptions_adjusted_per90", "ground_duels_won_adjusted_per90", "air_duels_won_adjusted_per90"]]
#take only necessary columns
adjusted_columns = salah_adjusted.columns[:]
#values
values = [salah_adjusted[column].iloc[0] for column in adjusted_columns]
#percentiles
percentiles = [int(stats.percentileofscore(summary_adjusted[column], salah_adjusted[column].iloc[0])) for column in adjusted_columns]
names = names = ["non-penalty Expected Goals", "non-penalty Goals", "Assists", "Key Passes", "Smart Passes", "Passes Ending in Final Third", "Passes Received in Final Third", "Offensive Ground Duels Won", "Air Duels Won"]
baker = PyPizza(
params=names, # list of parameters
straight_line_color="#000000", # color for straight lines
straight_line_lw=1, # linewidth for straight lines
last_circle_lw=1, # linewidth of last circle
other_circle_lw=1, # linewidth for other circles
other_circle_ls="-." # linestyle for other circles
)
fig, ax = baker.make_pizza(
percentiles, # list of values
figsize=(10, 10), # adjust figsize according to your need
param_location=110,
slice_colors=slice_colors,
value_colors = text_colors,
value_bck_colors=slice_colors,
# where the parameters will be added
kwargs_slices=dict(
facecolor="cornflowerblue", edgecolor="#000000",
zorder=2, linewidth=1
), # values to be used when plotting slices
kwargs_params=dict(
color="#000000", fontsize=12,
va="center"
), # values to be used when adding parameter
kwargs_values=dict(
color="#000000", fontsize=12,
zorder=3,
bbox=dict(
edgecolor="#000000", facecolor="cornflowerblue",
boxstyle="round,pad=0.2", lw=1
)
) # values to be used when adding parameter-values
)
# add title
fig.text(
0.515, 0.97, "Mohammed Salah per 90 (possesion adjusted) - Liverpool FC", size=18,
ha="center", color="#000000"
)
# add subtitle
fig.text(
0.515, 0.942,
"Percentile Rank vs Premier League Forwards | Season 2017-18",
size=15,
ha="center", color="#000000"
)
plt.show()
Total running time of the script: ( 2 minutes 0.704 seconds)