Note
Click here to download the full example code
Calculating xT (action-based)
Calculate action based Expected Threat once you have found possession chains.
import pandas as pd
import json
# plotting
import os
import pathlib
import warnings
from joblib import load
from mplsoccer import Pitch
from itertools import combinations_with_replacement
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
import numpy as np
pd.options.mode.chained_assignment = None
warnings.filterwarnings('ignore')
Opening the dataset
First we open the data. It is the file created in the Possesion Chain segment. The files that we open are available here here. There are prepared using the script from the previous section.
df = pd.DataFrame()
for i in range(11):
file_name = 'possession_chains_England' + str(i+1) + '.json'
path = os.path.join(str(pathlib.Path().resolve().parents[0]), 'possession_chain', file_name)
with open(path) as f:
data = json.load(f)
df = pd.concat([df, pd.DataFrame(data)], ignore_index = True)
df = df.reset_index()
Preparing variables for models
For our models we will use all non-linear combinations of the starting and ending x coordinate and c - distance from the middle of the pitch. We create combinations with replacement of these variables - to get their non-linear transfomations. As the next step, we multiply the columns in the combination and create a model with them.
#model variables
var = ["x0", "x1", "c0", "c1"]
#combinations
inputs = []
#one variable combinations
inputs.extend(combinations_with_replacement(var, 1))
#2 variable combinations
inputs.extend(combinations_with_replacement(var, 2))
#3 variable combinations
inputs.extend(combinations_with_replacement(var, 3))
#make new columns
for i in inputs:
#columns length 1 already exist
if len(i) > 1:
#column name
column = ''
x = 1
for c in i:
#add column name to be x0x1c0 for example
column += c
#multiply values in column
x = x*df[c]
#create a new column in df
df[column] = x
#add column to model variables
var.append(column)
#investigate 3 columns
df[var[-3:]].head(3)
Calculating action-based Expected Threat values for passes
To calculate action-based Expected Threat values for passes we use a two-step process.
Step 1: Predicting if a pass belongs to a chain ending with a shot
We use logistic regression (XGBoost classifier) to predict whether a pass belongs to a possession chain that ends with a shot. The outcome variable is binary (True/False), representing whether the chain ended with a shot. Here we load a pre-trained model trained on Bundesliga data, using the xgboost library version 1.6.2. The training steps are provided in the commented section below.
Step 2: Predicting the xG value of that shot
For passes predicted to end in a shot, we use linear regression to predict the Expected Goals (xG) value of that shot. The outcome variable here is continuous, ranging from 0 to 1.
The product of these two probabilities gives us our action-based Expected Threat (xT) statistic
### TRAINING, it's not perfect ML procedure, but results in AUC 0.2 higher than Logistic Regression ###
#passes = df.loc[ df["eventName"].isin(["Pass"])]
#X = passes[var].values - note that this is different X, with data from BL
#y = passes["shot_end"].values
#X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.1, random_state = 123, stratify = y)
#xgb = XGBRegressor(n_estimators = 100, ccp_alpha=0, max_depth=4, min_samples_leaf=10,
# random_state=123)
#from sklearn.model_selection import cross_val_score
#scores = cross_val_score(estimator = xgb, X = X_train, y = y_train, cv = 10, n_jobs = -1)
#print(np.mean(scores), np.std(scores))
#xgb.fit(X_train, y_train)
#print(xgb.score(X_train, y_train))
#y_pred = xgb.predict(X_test)
#print(xgb.score(X_test, y_test))
#predict if ended with shot
passes = df.loc[df["eventName"].isin(["Pass"])]
X = passes[var].values
y = passes["shot_end"].values
#path to saved model
path_model = os.path.join(str(pathlib.Path().resolve().parents[0]), 'possession_chain', 'finalized_model.sav')
model = load(path_model)
#predict probability of shot ended
y_pred_proba = model.predict_proba(X)[::,1]
passes["shot_prob"] = y_pred_proba
#OLS
shot_ended = passes.loc[passes["shot_end"] == 1]
X2 = shot_ended[var].values
y2 = shot_ended["xG"].values
lr = LinearRegression()
lr.fit(X2, y2)
y_pred = lr.predict(X)
passes["xG_pred"] = y_pred
#calculate xGchain
passes["xT"] = passes["xG_pred"]*passes["shot_prob"]
passes[["xG_pred", "shot_prob", "xT"]].head(5)
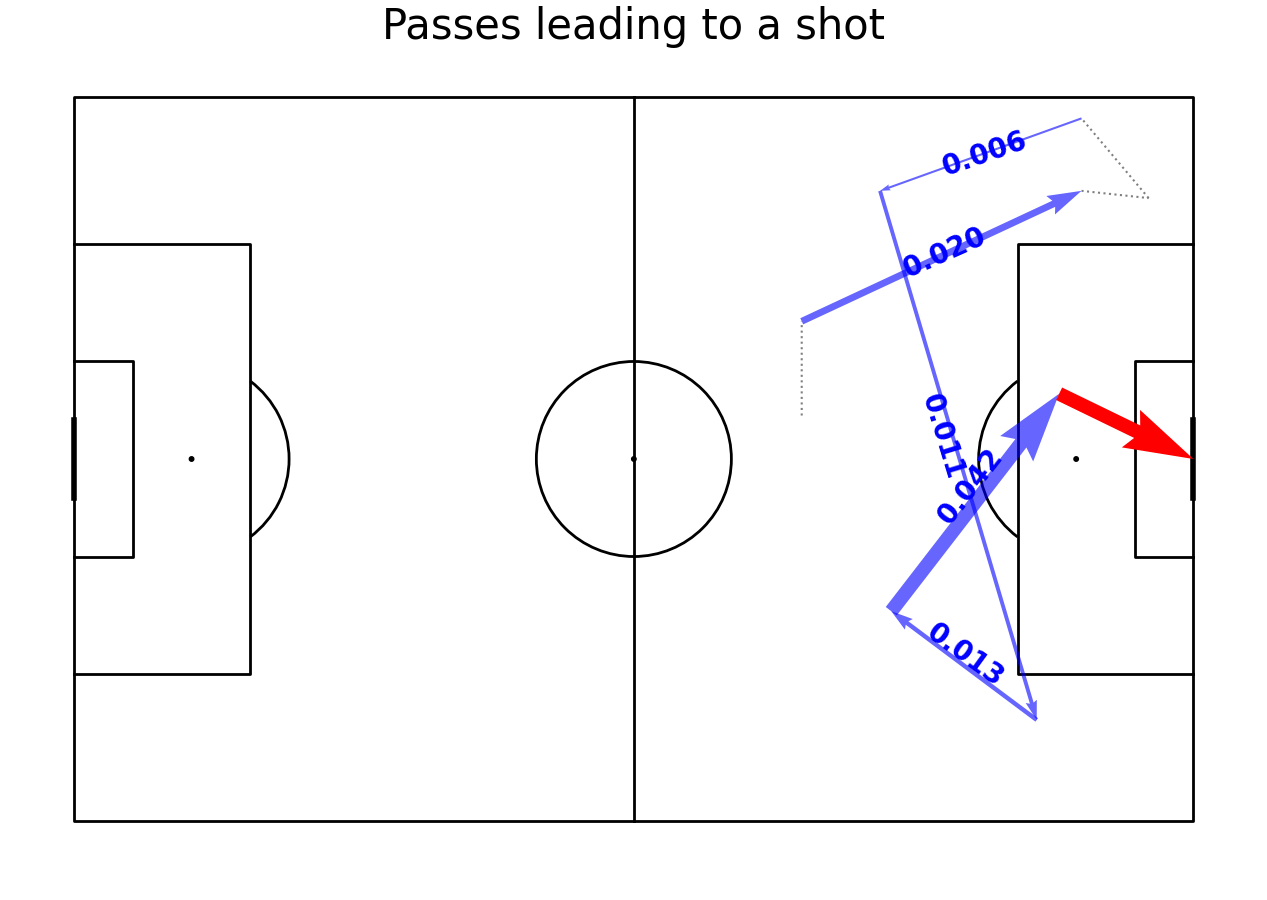
Making a plot of pass values
Now we can make the plot of the pass. This is the same plot as we have seen in previous section but this time the value is assigned to passes and line width is proportional to its value.
chain = df.loc[df["possesion_chain"] == 4]
#get passes
passes_in = passes.loc[df["possesion_chain"] == 4]
max_value = passes_in["xT"].max()
#get events different than pass
not_pass = chain.loc[chain["eventName"] != "Pass"].iloc[:-1]
#shot is the last event of the chain (or should be)
shot = chain.iloc[-1]
#plot
pitch = Pitch(line_color='black',pitch_type='custom', pitch_length=105, pitch_width=68, line_zorder = 2)
fig, ax = pitch.grid(grid_height=0.9, title_height=0.06, axis=False,
endnote_height=0.04, title_space=0, endnote_space=0)
#add size adjusted arrows
for i, row in passes_in.iterrows():
value = row["xT"]
#adjust the line width so that the more passes, the wider the line
line_width = (value / max_value * 10)
#get angle
angle = np.arctan((row.y1-row.y0)/(row.x1-row.x0))*180/np.pi
#plot lines on the pitch
pitch.arrows(row.x0, row.y0, row.x1, row.y1,
alpha=0.6, width=line_width, zorder=2, color="blue", ax = ax["pitch"])
#annotate text
ax["pitch"].text((row.x0+row.x1-8)/2, (row.y0+row.y1-4)/2, str(value)[:5], fontweight = "bold", color = "blue", zorder = 4, fontsize = 20, rotation = int(angle))
#shot
pitch.arrows(shot.x0, shot.y0,
shot.x1, shot.y1, width=line_width, color = "red", ax=ax['pitch'], zorder = 3)
#other passes like arrows
pitch.lines(not_pass.x0, not_pass.y0, not_pass.x1, not_pass.y1, color = "grey", lw = 1.5, ls = 'dotted', ax=ax['pitch'])
ax['title'].text(0.5, 0.5, 'Passes leading to a shot', ha='center', va='center', fontsize=30)
plt.show()
Finding out players with highest action-based Expected Threat
As the last step we want to find out which players who played more than 400 minutes scored the best in possesion-adjusted action-based Expected Threat per 90. We repeat steps that you already know from Radar Plots. We group them by player, sum, assign merge it with players database to keep players name, adjust per possesion and per 90. Only the last step differs, since we stored percentage_df in a .json file that can be found here.
summary = passes[["playerId", "xT"]].groupby(["playerId"]).sum().reset_index()
#add player name
path = os.path.join(str(pathlib.Path().resolve().parents[0]),"data", 'Wyscout', 'players.json')
player_df = pd.read_json(path, encoding='unicode-escape')
player_df.rename(columns = {'wyId':'playerId'}, inplace=True)
player_df["role"] = player_df.apply(lambda x: x.role["name"], axis = 1)
to_merge = player_df[['playerId', 'shortName', 'role']]
summary = summary.merge(to_merge, how = "left", on = ["playerId"])
#get minutes
path = os.path.join(str(pathlib.Path().resolve().parents[0]),"minutes_played", 'minutes_played_per_game_England.json')
with open(path) as f:
minutes_per_game = json.load(f)
#filtering over 400 per game
minutes_per_game = pd.DataFrame(minutes_per_game)
minutes = minutes_per_game.groupby(["playerId"]).minutesPlayed.sum().reset_index()
summary = minutes.merge(summary, how = "left", on = ["playerId"])
summary = summary.fillna(0)
summary = summary.loc[summary["minutesPlayed"] > 400]
#calculating per 90
summary["xT_p90"] = summary["xT"]*90/summary["minutesPlayed"]
#adjusting for possesion
path = os.path.join(str(pathlib.Path().resolve().parents[0]),"minutes_played", 'player_possesion_England.json')
with open(path) as f:
percentage_df = json.load(f)
percentage_df = pd.DataFrame(percentage_df)
#merge it
summary = summary.merge(percentage_df, how = "left", on = ["playerId"])
#adjust per possesion
summary["xT_adjusted_per_90"] = (summary["xT"]/summary["possesion"])*90/summary["minutesPlayed"]
summary[['shortName', 'xT_adjusted_per_90']].sort_values(by='xT_adjusted_per_90', ascending=False).head(5)
Challenge
1. StatsBomb has recently released a dataset with Indian Superleague 2021/22 games. Calculate xGchain values for these player. Note that the possesion chains are already isolated. Which player stood out the most?
Total running time of the script: ( 0 minutes 6.335 seconds)