Note
Click here to download the full example code
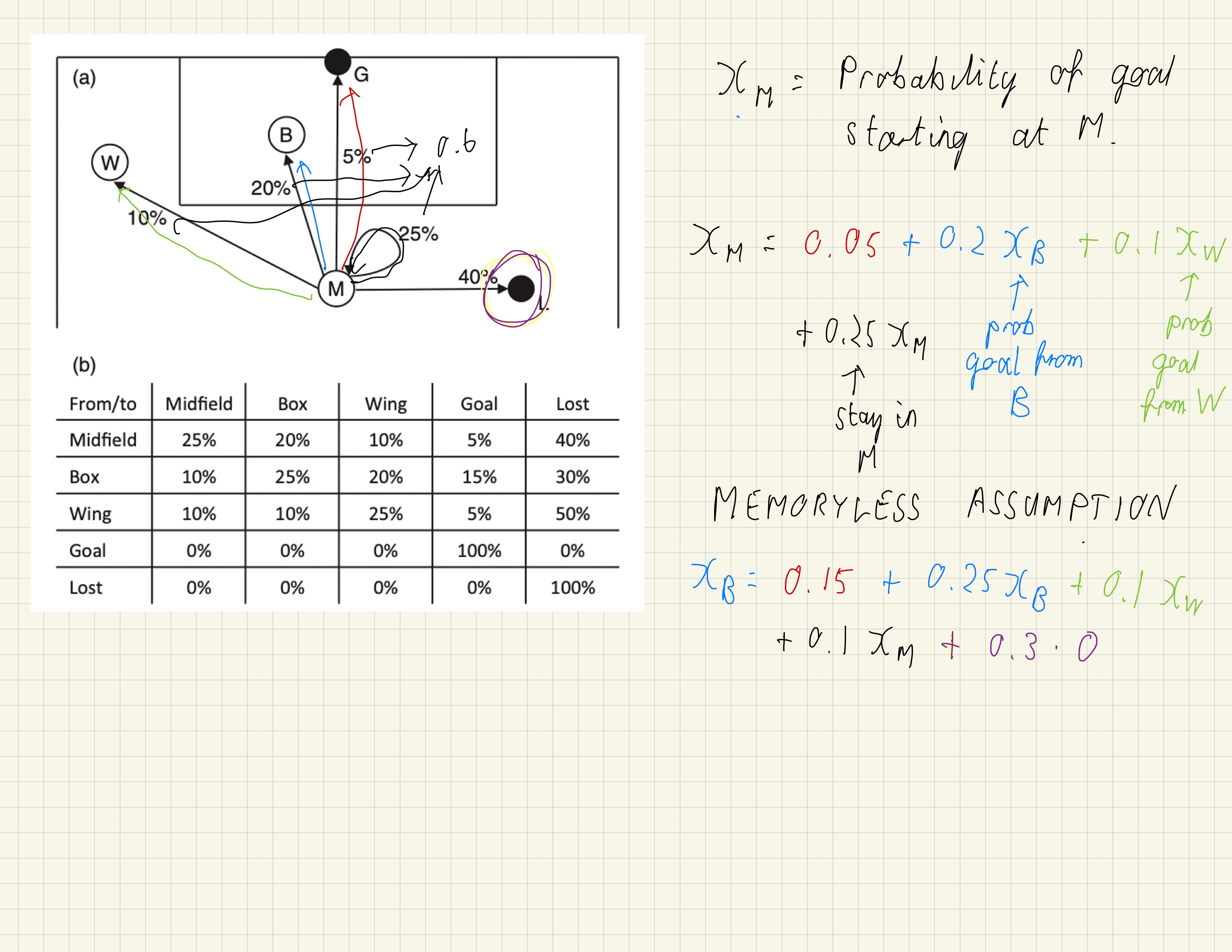
Markov chains
Here we look at how to formulate expected threat in terms of a Markov chain. First watch the video
import numpy as np
Setting up the matrix
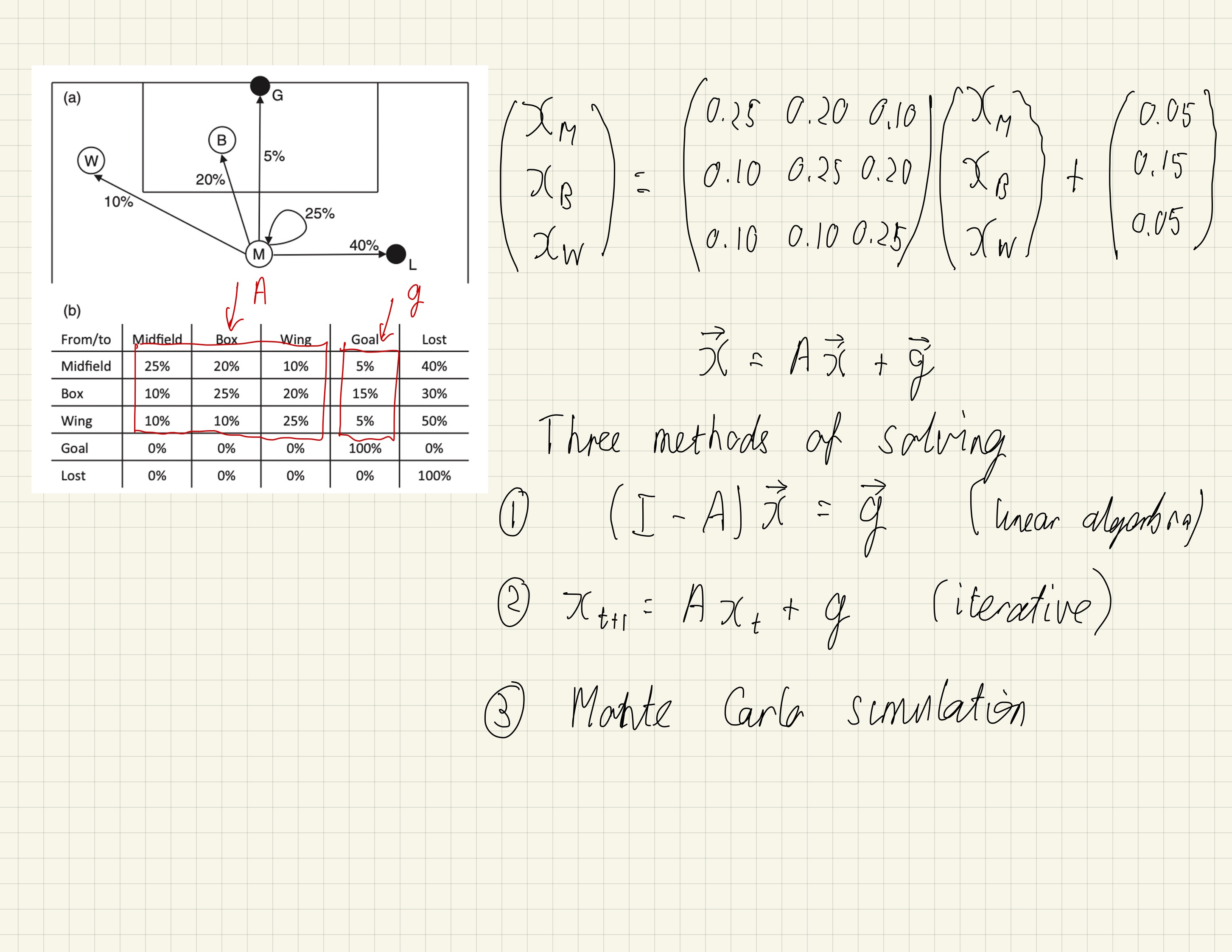
We first set up the pass matrix A and the goal vector g.
#Pass matrix
A = np.matrix([[0.25, 0.20, 0.1], [0.1, 0.25, 0.2],[0.1, 0.1, 0.25]])
#Goal vector
g = np.transpose(np.matrix([0.05, 0.15, 0.05]))
Linear algebra method
Here we solve (I-A)xT = g
xT1 = np.linalg.solve(np.identity(3) - A,g)
print('Expected Threat')
print('Central, Box, Wing')
print(np.transpose(xT1))
Expected Threat
Central, Box, Wing
[[0.14991763 0.25205931 0.12026359]]
Iterative method
Here we iterate xT’ = A xT + g to update through each move of the ball
xT2=np.zeros((3,1))
for t in range(10):
#print(np.matmul(A,xT2) + g)
xT2 = np.matmul(A,xT2) + g
print('Expected Threat')
print('Central, Box, Wing')
print(np.transpose(xT2))
Expected Threat
Central, Box, Wing
[[0.14966911 0.25182476 0.12007973]]
Simulation method
Here we simulate num_sim possessions, starting from each of the three areas.
num_sims=10
xT3=np.zeros(3)
description = {0: 'Central', 1: 'Wing', 2: 'Box' }
for i in range(3):
num_goals = 0
print('---------------')
print('Start from ' + description[i] )
print('---------------')
for n in range(num_sims):
ballinplay=True
#Initial state is i
s = i
describe_possession=''
while ballinplay:
r=np.random.rand()
# Make commentary text
describe_possession = describe_possession + ' - ' + description[s]
#Cumulative sum of in play probabilities
c_sum=np.cumsum(A[s,:])
new_s = np.sum(r>c_sum)
if new_s>2:
#Ball is either goal or out of play
ballinplay=False
if r < g[s] + c_sum[0,2]:
#Its a goal!
num_goals = num_goals + 1
describe_possession = describe_possession + ' - Goal!'
else:
describe_possession = describe_possession + ' - Out of play'
s = new_s
print(describe_possession)
xT3[i] = num_goals/num_sims
print('\n\n---------------')
print('Expected Threat')
print('Central, Box, Wing')
print(xT3)
---------------
Start from Central
---------------
- Central - Central - Central - Central - Central - Out of play
- Central - Out of play
- Central - Out of play
- Central - Wing - Central - Out of play
- Central - Wing - Out of play
- Central - Central - Out of play
- Central - Out of play
- Central - Out of play
- Central - Wing - Out of play
- Central - Out of play
---------------
Start from Wing
---------------
- Wing - Out of play
- Wing - Goal!
- Wing - Out of play
- Wing - Central - Wing - Box - Out of play
- Wing - Box - Out of play
- Wing - Out of play
- Wing - Out of play
- Wing - Box - Out of play
- Wing - Goal!
- Wing - Central - Out of play
---------------
Start from Box
---------------
- Box - Out of play
- Box - Box - Out of play
- Box - Out of play
- Box - Box - Box - Box - Out of play
- Box - Out of play
- Box - Out of play
- Box - Box - Box - Out of play
- Box - Box - Out of play
- Box - Central - Out of play
- Box - Out of play
---------------
Expected Threat
Central, Box, Wing
[0. 0.2 0. ]
Here I work through the derivation of equations for xT
Here I outline how we write this in matrix form:
Total running time of the script: ( 0 minutes 0.004 seconds)